A lot of us use the Linux shell. Some of us use it because it is a part of our job. Some of us use it because we use Linux in our personal machines and we like it. Some of us are in universities, and are working in Linux systems for our projects. Some shellscript users are developers, while some work in dev-ops.
Whatever be the reason, people from many walks of software use Linux shells. Hardcore fans of the shell would point out that what we do use is formally known as the Bourne Again Shell, or bash for short. I am aware of this, but I will simply call it the shell for simplicity here.
I have come across several memes on the internet bemoaning the difficulties of using shellscript. While the nerdier among us who have long experienced shellscripts may find the nuances of shellscript refreshingly original and distinct, most of the dialog around the language in the internet is concerned with bashing the bash language (pun intended) for being a brutally confusing mess.
Given the extent of chaos and confusion surrounding bash I think some order is in order (pun intended again! ) here. I am going to discuss bash and talk about its nuances, with the intention of making the language less confusing for the reader, and providing insight and understanding about its conventions, syntax and philosophy.
The Language and the Reputation
Few programming languages have the kind of negative publicity as the Linux shellscript. PHP is one of the few languages that can even compare with shellscript in terms of reputation. People outside of the Linux geek fold seem to hate it with a passion, and quite possibly with a vengeance.
I came across a tweet by Jake Wharton recently where he alleges that “coding in shellscript” is the opposite of “riding a bike”. The idiom “riding a bike” is used to denote certain activities which require some skill, but quickly become instinct once we get the hang of it. Familiarity comes so strongly with riding a bike that once you have learnt to ride a bike, it is actually difficult to forget the art.
The opposite is true, according to Wharton, for the Linux shellscript. Every time you need to write a little bit of shellscript code, you need to look up the syntax and nuances of the language from the internet.
As a devops engineer who has been working extensively in Linux, let me try to bridge the gap between shellscript and people who would like to make shellscript do something useful. Shellscript is an integral part of Linux, since it is the language in which commands are fed to the operating system. It is possible to make shellscript do almost anything for you, but it is tricky.
What is the difference?
So how is bash different from other languages? How does it differ from, say, Java or Python? To put it bluntly, there is very little about bash that is in common with those languages. The bash language is not just a different breed of programming language, it is from an entirely different taxonomical kingdom!
The first difference, of course, is the way variables work. In bash, all atomic variables are strings. There are no integer, float or other variables. All variables are either strings or arrays, and that’s basically that.
Moreover, atomic variables can have arithmetic, comparison or logical operations done on them. But the variables - both the inputs and the outputs of these operations - are strings. The arithmetic and comparison operators work by parsing the strings into numbers, processing the numbers arithmetically, and then dumping the result into a string again.
This has to do with the Unix philosophy, where all data is passed around as human-readable strings. If a program prints an output, it has to be a string. If a program reads an input, it has to be a string. So it makes sense that the Unix shell ought to simply treat all data as strings to begin with.
The second is the matter of keywords. All programming languages have their own keywords. Shellscript is no exception. However, the commands in shell are not keywords. The commands, in fact, are executable programs. The keywords are fg, if, then, fi, while, for, in, do, done, export, disown, function , return, read and the like.
And that brings us to a very important point about shellscript - while other languages get new functions and classes from libraries, shellscript simply uses existing executables as commands. And that is shellscript’s very purpose - to tie together different executable scripts into functioning “programs”, where the output of one is passed as input to another. Shellscript uses complete programs - including those compiled in Java, C or C++, composed in Javascript, Python, Lua or even Shellscript itself - as its functions and subroutines! (of course, I am being figurative here - shellscript has functions, but that’s another story)
The third difference is that shellscript is extremely sensitive to empty spaces. In C, Java, JS and the like, putting an accidental empty space here or there is not an issue. But in shellscript? export x=1 and export x = 1 are not the same things. The former assigns the value 1 to the variable x, while the latter raises an immediate error.
Likewise, leaving an extra space can also have dire consequences. While C might treat x b and x  b as the same thing, there is no guarantee that shellscript will do so. The result varies from case to case.
With that, lets begin discussing shellscript.
The parts of Shellscript
I will explain the nuances of shellscript in five stages - commands, variables, loops, arrays and functions. Concepts like piping are tied into these stages - piping, for instance, is a part of the way commands work, so they are part of commands.
1. Commands
Shellscript commands are programs. Anything that can be executed is a legible shellscript command. But to become a command, the executable must be stored in a PATH location. This is a tricky bit of spoiler which ties in with variables, so I will defer the explanation of how this works for now. But to give a basic understanding of this concept, I will briefly discuss the PATH.
There are certain special folders in a Linux system which are called path locations. You can add a folder to the list of path locations, or you can remove a folder from it. But for now, we will assume that the path folders are magical and special, and that they innately possess this mystical feature which makes any executable file in them become commands.
This command will give you a series of folder locations separated by colons (the : symbol):
echo $PATH
Each of these locations is a path location. Programs in these locations are commands.
Commands which are built for Linux and tailored to work with shellscript are called “POSIX compatible”. These programs have special features. For one thing, they draw in two inputs and release two outputs, in addition to any file they may create.
|
|
|---|
|
Figure 1-1: the inputs and outputs of a POSIX command |

Each of these inputs and outputs is relevant.
-
When you run the command, it has a name. The part that comes after the name are the command line arguments.
-
Every command is a program, and it can read inputs from the keyboard. Inputs read from the keyboard are called the standard input of the program.
-
Every command is a program, and it can print outputs to the terminal (which is what we call the “command prompt” in Linux, in case you are not familiar with the word “terminal”). Outputs printed into the terminal is called the standard output.
-
Alongside this, there is a separate output which also goes to the terminal, but which is separate from the standard output in ways that I will discuss later in this article. Its called the standard error.
-
Finally, every single command returns a value, which is a single four-byte number. This number is typically 0 if the program ran properly. If the program was forced to shut down due to an error, this number is a specific non-zero value corresponding to the error. We call this number the return value.
These are the parts of a command. It is useful to explain these with an example. I will provide the example of grep, which is a fairly standard command, albeit a very powerful command if used correctly.
The grep command accepts two main inputs in the command line - a search term and a file name. It will search for every single line in the file for the term, and it will print the lines which have the term. Here is a sample of its use:
|
|
|---|
|
Figure 1-2: a sample use of the |

Interestingly, the grep command also works on Unicode strings, which is to say, strings full of special characters (such as ℕ or × or α) and also characters in other languages, such as Hindi poems in Devanagari:
|
|
|---|
|
Figure 1-3: Using the |
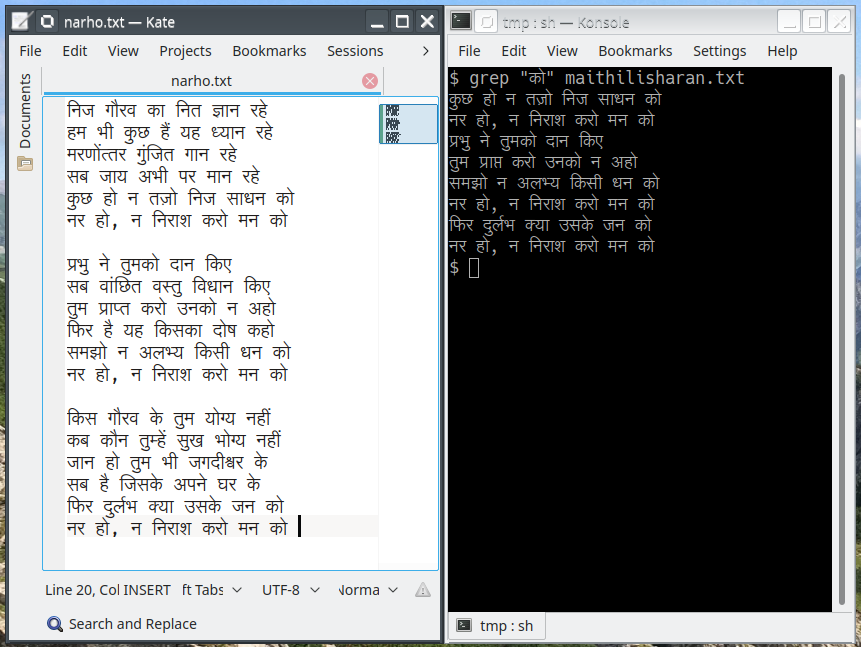
This is because the bash shell, unlike Windows Command Prompt, is Unicode-compatible. In fact, the bash shell is designed to be used alongside these commands. It is even possible to create commands using Unicode characters, although this is not advisable, unless you have a keyboard that types out the unicodes without the need for any special software.
There are three fundamental things we need to understand about commands to be able to use them properly. They are Piping Commands, Redirecting I/O and Command Line Arguments.
These three things require further discussion, and we will cover them one at a time.
(i) Command Line Arguments
Commands can take additional arguments to specify something about their intended action. These additional arguments are added after the name of the command. For instance, when running the grep command, we specify the word we are looking for, as well as the name of the file in which to search for the word.
The command
grep "word" filename.txt
will look for the word word inside the file filename.txt. These two additional bits of text following after the word grep are called Command Line Arguments.
There are many kinds of Command Line Arguments, but one of the most useful to learn about is the flag. Flags come in many shapes and sizes, and vary in both form and function. But essentially, a flag is an optional modifier which changes the behavior of a command.
All
For instance, consider this text:
|
|
|---|
|
Figure 1-4: Default use of the |

We are looking for instances of the word but here, and there are several lines in the poem which has the word. For instance, consider the fourth line:
But it lacked a certain force
This line clearly has the word But in it, but this word is not detected. Why? Because the grep command runs character-by-character search, and the default option is case-sensitive search. This is because grep is meant to be used to search code, and code is always case-sensitive.
So But and but are not the same thing. One shows up in the search output, but the other does not. Suppose we need to see all instances of the word “but” - regardless of case - then what do we do?
|
|
|---|
|
Figure 1-5: Using the |

What we can do is to use the -i flag with the command. This -i in the command - notice the image above - makes grep behave in a case-insensitive manner. It will now look for all lines containing the word “but”, regardless of whether the letters are in the upper or lower case.
All flags begin with a hyphen: a - symbol. In Linux jargon, we refer to this hyphen as a tick. So the command above, when spoken out aloud, would be pronounced as:
“grep tick-’I’ but vikram-seth-dot-tee-ex-tee”
In a way, these arguments constitute an input to the command. They provide information to the command about what to do and how to do it.
So fundamentally, there are two kinds of command line arguments:
- Commands (Sometimes called sub-commands) or Targets, which tell the command what to act on - for instance, for the
grepcommand, they will mention the target word to search for and the file in which to search for it. It is a bit weird to think of them as “commands”, since that is what we call the command itself to which we are passing them as arguments. But the name is what the name is. As I mentioned before, the command itself is an executable. These arguments are like the commands to that executable.Flags or Options, which modify the behavior of the command in specific ways. These flags may in turn require arguments of their own.
Let me list four different flags that go with the grep command:
|
Flag |
Description |
|---|---|
|
|
Case Insensitive Search |
|
|
Inverse Search (print those lines which do not have the search term) |
|
|
Context |
|
|
Color Mode: The value of # can be |
As you can see, some flags need no argument and introduce modifications by merely being present, such as -i and -v. Other flags do need arguments, and these arguments tell us how those flags in turn will modify the function of the command. Basically, these flags are like keyword arguments in Python: --color=# for instance is like typing color=”#” inside the parenthesis of a function call in Python.
The man command accepts the name of a command as argument (not a flag), and it prints out a manual of the command - its targets, its flags, what it does and how to use it. For instance, here is the output of man head, since the manual for the head command is much smaller:
HEAD(1) User Commands HEAD(1)
NAME
head - output the first part of files
SYNOPSIS
head [OPTION]... [FILE]...
DESCRIPTION
Print the first 10 lines of each FILE to standard out‐
put. With more than one FILE, precede each with a
header giving the file name.
With no FILE, or when FILE is -, read standard input.
Mandatory arguments to long options are mandatory for
short options too.
-c, --bytes=[-]NUM
print the first NUM bytes of each file; with the
leading '-', print all but the last NUM bytes of
each file
-n, --lines=[-]NUM
print the first NUM lines instead of the first
10; with the leading '-', print all but the last
NUM lines of each file
-q, --quiet, --silent
never print headers giving file names
-v, --verbose
always print headers giving file names
-z, --zero-terminated
line delimiter is NUL, not newline
--help display this help and exit
--version
output version information and exit
NUM may have a multiplier suffix: b 512, kB 1000, K
1024, MB 1000*1000, M 1024*1024, GB 1000*1000*1000, G
1024*1024*1024, and so on for T, P, E, Z, Y.
AUTHOR
Written by David MacKenzie and Jim Meyering.
REPORTING BUGS
GNU coreutils online help: <https://www.gnu.org/soft‐
ware/coreutils/>
Report head translation bugs to <https://translation‐
project.org/team/>
COPYRIGHT
Copyright © 2018 Free Software Foundation, Inc. Li‐
cense GPLv3+: GNU GPL version 3 or later
<https://gnu.org/licenses/gpl.html>.
This is free software: you are free to change and re‐
distribute it. There is NO WARRANTY, to the extent
permitted by law.
SEE ALSO
tail(1)
Full documentation at: <https://www.gnu.org/soft‐
ware/coreutils/head>
or available locally via: info '(coreutils) head invo‐
cation'
GNU coreutils 8.30 September 2019 HEAD(1)
I am going to end this article here, since it is getting very long. In the next article, I will discuss how commands are piped together, and how we can chain up long pipelines of these commands to generate complex functionality.




I read a lot about Linux but for me the latest version of Windows is much more convenient to use. The more that on this website you can buy this system really cheaply and legally: https://royalcdkeys.com/
I dunno, man, Windows just feels odd and outlandish to me these days, now that I have found a home in the NIX side of things.